Interactions between Processes and Device Drivers
Consider a C program running on a unix based computer. The program
has been running for a while, so we don't have to think about how things
get set up. It is reading data in text form from a file. It has already
read a few lines, and is about to read some more.
After a little
computation, the program calls the function getc() to read the next
character from the file. getc() is part of the standard C library
"stdio", not part of the operating system. getc() was written by people who
know how the system works, and who want to make things run as smoothly and
efficiently as possible. They realised that if getc() actually reads the
next character from the disc every time it is called, programs will run
very slowly (if it takes 10mS on average to make a disc access, a file
like this with a few thousand characters would take over a minute to
read).
To avoid terrible
inefficiency, getc() and all the other input and output functions in
stdio, use a buffer: a largeish array of characters kept aside for later
use. The first time a program calls getc(), it has no choice but to read
data from the disc. Instead of just reading the one character requested,
it will read a whole lot at the same time, at least a block (512
characters) and maybe more. All these characters are kept in the buffer,
so that next time getc() is called it can just take the next one
immediately without taking the time to perform a disc read operation.
This way, we only have to do one disc operation for every 512 (or more)
characters read, so the program should run approximately 512 times faster.
If you looked inside
stdio.c, the C library file where all the stdio functions are defined,
you would see something along these lines:
struct file_data
{ char buffer[512];
int next_char_pos;
int chars_in_buffer;
int file_reference;
.... };
typedef struct file_data FILE;
FILE *fopen(char *name, char *mode)
{ if (strcmp(mode,"r"))
{ FILE *newfile;
int file_ref=open(name,O_RDONLY);
if (file_ref<0)
{ maybe print an error message
return NULL; }
newfile=malloc(sizeof(FILE));
newfile->next_char_pos=0;
newfile->chars_in_buffer=0;
newfile->file_reference=file_ref;
return newfile; }
else
...... }
char getc(FILE *f)
{ char answer;
if (f==NULL)
return EOF;
if (f->next_char_pos >= f->chars_in_buffer)
{ refill_buffer(f);
if (f->chars_in_buffer <= 0)
return EOF;
f->next_char_pos=0; }
answer=f->buffer[f->next_char_pos];
f->next_char_pos+=1;
return answer; }
void refill_buffer(FILE *f)
{ int num_read;
num_read=read(f->file_reference, f->buffer, 512);
f->chars_in_buffer=num_read;
f->next_char_pos=0; }
char *fgets(char *string, int maxnum, FILE *f)
{ int ptr=0;
while (ptr<maxnum)
{ char c=getc(f);
if (c==EOF)
{ if (ptr==0)
return NULL;
else
break; }
string[ptr]=c;
ptr+=1;
if (c=='\n') break; }
string[ptr]='\0';
return string; }
Of course, things would be rather more complicated as they always are in
real life, but that is a pretty accurate picture. When you open a file
using the C library function fopen(), the fopen() function delegates all
the real work to the unix library function open(). open() is part of the
operating system, it knows how unix files work, and can handle them
properly; any program written in any language running under unix can call
on open() in principle. fopen() is part of the C library; all C compilers,
no matter what kind of computer they are running on, must provide a
fopen() function that works in exactly the same way. This allows C
programmers to write transportable programs. You can rely on fopen()
always being there and always working in exactly the same way, no matter
where your program is running. Each C compiler for each different kind of
computer and each different kind of operating system must provide a
different implementation of fopen() in order to guarantee this constancy.
fopen()s written for unix systems can rely on open() open being there, but
for other systems they will have to do something else. This is one of the
things you find out when writing your file-system project.
So, fopen() lets
open() do all the dirty work. open() returns as its result a small integer
that identifies the open file. All future file operations must provide
that integer to indicate which file is to be operated on. fopen() creates
a special data structure called a FILE to hold that vital number and
some other information. fopen() also sets aside the 512 bytes for the
buffer, and a couple of variables to keep track of how full the buffer is.
All this stuff goes in the FILE data structure. From now on, all C library
i/o functions pass around a pointer to that structure (a FILE * variable)
to gain access to the essential information.
When your program
calls getc(), it provides the FILE * as a parameter:
FILE *f=fopen("afile","r");
....
c=getc(f);
When getc() notices that its buffer is empty, it has to replenish the
buffer by performing a real read of data from disc. Under unix, there is a
function called read() (again part of the unix library, not the C library)
which actually does all the work (or at least sets things in motion).
read() is given three parameters: the file identifier, an indication of
how much to read, and a pointer to the place in memory to put it all. It
returns as its result the number of bytes it actually succeeded in
reading. This information is used to reset the buffer-fullness variables
appropriately.
If we pretend that
read() actually does all the work of reading data from a disc file itself
(and under a really primitive operating system like DOS, this could
be the case), that is all there is to it. We could chart the programs
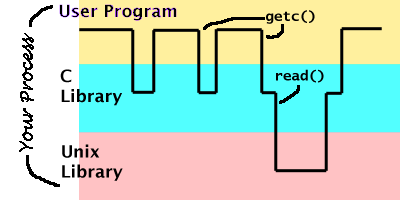
progress through the different layers of the system. Normally when your
program is running, it is executing top-level code written by you. When
it calls getc(), it dips down into the next layer, the C run-time
library, which is hardly scratching the surface really: there is nothing
special about the stdio library, normal users are perfectly free to write
their own version of it. Occasionally, the C run-time library will have to
dip down into the next layer to do some real work, by calling open() or
read(). Here you are actually executing operating system code, but it is
still your normal, unpriviliged process that is doing it.
In graph form, it
would look like this:
Unfortunately, there
is more to it than that. In a real operating system, read() can't possibly
be allowed direct control of the discs. There could be hundreds of users
all wanting to use the disc at the same time, so there has to be some
central component to handle all the requests in a reasonable and
efficient way.
The read() function
simply passes the buck further down the line, but this time, a message is
sent to some other "process" to request that the work should be done.
read() constructs a little packet of data called an I/O Request Packet or
IRP for short (this is really just a special kind of data structure that
the operating system knows about). The IRP says how much data is to be
read form which file, and where it is to be put (essentially the three
parameters that were given to read()), together with the identification
number (or name) of the process that wants the data (i.e. the PID of your
process). When the IRP has been created, read() uses a very special
operating system function to add the IRP to the end of a special queue of
similar IRPs. All IRPs requesting disc activity are put on the end of the
same queue (so there is just one such queue in the whole system). The
"process" that directly controls the disc system takes these packets
from that queue and deals with them when it is ready.
So, read() uses
a special system function (often called QIO(), for Queue Input/Output
request) to add an IRP to the end of a queue. The special function QIO()
has to be used because there is only one queue for disc requests in the
whole system; it is a shared resource that every process adds data to at
radom moments. QIO() has to be very careful to use semaphores properly
to ensure that the queue soes not get destroyed by concurrent accesses.
Once the IRP has been
added to the queue, it could be some time before it is processed. There is
nothing your program can do in the mean time (if you called getc(), and
it returned before it had read the character, you would not be very
happy), so it goes to sleep. Once an IRP is added to the queue, the
process voluntarily goes to sleep. It does not return to the user program
yet, it goes to sleep while still executing the read() function.
When your IRP
is eventually processed, and the requested data is ready, your process
is woken up (that is why the PID has to be saved in the IRP. Otherwise
nobody would know who to wake when the data is ready). The read() function
continues executing as though nothing has happened, except that it can now
be confident that the requested data is ready, and it can return that data
to getc(), which can in turn put the data in its buffer and return one
character of it to the user program.
Extending the graph to
include this, we have:
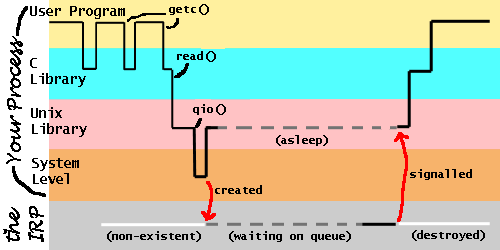
The "process" that takes IRPs off the queue and deals with them is not
usually a true process. There is no real reason why it souldn't be one, it
just usually isn't. It is a Device Driver. Every real peripheral, such as
a disc system, a line printer, or an ethernet card, has a dedicated device
driver. Device drivers all do more or less the same thing. They spend
their entire lives looking after the device that they are responsible for.
Whenever they are not performing an essential task for the device, they
will take the first IRP off their queue and deal with it. In the case of
a disc device driver, that "dealing with" can usually only be the
beginning of an operation. When an IRP that requests a read-from-disc
operation is processed, the device driver will send the signals to the
disc drive telling it to prepare to read the requested data, but until
the disc rotates to the correct position and the heads settle over the
correct track, there is nothing more to be done. The device driver may
set the partially processed IRP aside, and deal with some others.
Eventually the device
driver will receive a signal from the disc saying that some data is ready.
It will then search through its list of set-aside IRPs until it finds the
one whose data is nor arriving. That IRP tells it where to put the data,
and which process to wake up. After the data is trasferred, the device
driver signals the relevant process to wake up, and destroys the IRP so
that the memory it occupies can be reused.
The input/output
operation is now complete, and the process that requested it continues
merrily computing. The IRP no longer exists, and the device driver
is continuing to deal with other IRPs as they appear in its queue.
A device driver is
a privileged almost-process always running in the background. It does all
the real work associated with its device; user and system processes ask it
to do things by adding little notes in the form of IRPs to its queue.
Some systems very confusingly refer to IRPs as "fork processes".